llms-101

ChatGPT (GPT 3.5) được giới thiệu rộng rãi tới end-user vào tháng 11/2022, giúp user trải nghiệm sản phẩm của OpenAI một cách dễ dàng và rẻ. Từ đó, một cuộc chạy đua kinh khủng trong lĩnh vực AI đã diễn ra từ rất nhiều các ông lớn, cùng nhiều startup làm về các sản phẩm AI ra đời.
Sự tiếp cận dễ dàng, cuộc chạy đua từ các mô hình, giá thành, tối ưu về phần cứng sử dụng, các sản phẩm (chat, IDE, agent, workflow …) liên tục được giới thiệu, tính ứng dụng (practical and functional) của các sản phẩm dẫn tới một thực tế “mỗi ngày chúng ta thức dậy, chúng ta cảm thấy lạc lõng và lỗi thời so với chính ngày hôm qua”. Có quá nhiều thuật ngữ mới được sinh ra, có quá nhiều sản phẩm mới được ra đời, thứ chúng ta biết ngày hôm qua, hôm nay nó đã lỗi thời và có thể sẽ bị thay thế trong vài tháng tới. Não bộ của con người phải vật lộn với mớ kiến thức mới, mớ kiến thức khổng lồ mà chính chúng ta cũng không biết nó đúng hay không (ngay cả chính những nội dung đang được viết này cũng vậy).
NHƯNG ai cũng hiểu, chúng ta không thể đứng ngoài vòng xoáy AI. Là một kỹ sư khởi động server, không đứng ngoài tới từ 2 khía cạnh:
- End-user: Hiểu, sử dụng, tận dụng các sản phẩm AI để giúp ích cho công việc như coding, nghiên cứu/học một lĩnh vực mới, giải quyết vấn đề. Bằng cách nghiên cứu về sản phẩm, tối ưu cách sử dụng, mua sản phẩm nào phù hợp giúp ích cho bản thân.
- Vận hành: Hiểu để có thể selfhost một model cho tới deploy, tuning và chạy được trên các môi trường production, các ML flow, đánh giá chi phí, lợi ích giữa các phương pháp triển khai.
Bài viết này là một sự cố gắng để bắt kịp, hiểu các thuật ngữ, khái niệm trong lĩnh vực AI, để hiểu người khác đang nói về vấn đề gì, để hiểu thế giới đang nói về vấn đề gì, để hiểu một sản phẩm AI, infra AI giải quyết vấn đề gì và có ý tưởng về tận dụng chúng giải quyết một vấn đề cụ thể nào đó tối ưu.
Mọi khái niệm chỉ dừng ở mức cơ bản, nhiều thuật ngữ mới, khó hiểu sẽ cố gắng so sánh với một thuật ngữ tương đương trong lĩnh vực khác cho dễ hiểu, hoàn toàn không có ý định đi sâu vào một vấn đề cụ thể.
- LLMs (Large Language Models) - mô hình ngôn ngữ lớn, chúng hoạt động bằng các nhận vào và trả ra văn bản. Các mô hình này được huấn luyện trên một lượng lớn dữ liệu văn bản từ wikipedia, reddit, sách, báo, các trang web giúp giải quyết nhiều nhiệm vụ khác nhau. Mô hình LLM GPT3.5 của OpenAI chính là phiên bản tiếp cận rộng rãi tới nhiều user khi user chỉ cần hỏi (input text) và nhận câu trả lời đúng ngữ cảnh, đúng ngữ pháp, hiểu ngôn ngữ tự nhiên và đôi khi khá hài hước.
- LMMs (Multimodal Models) - LLMs (text in, text out), nhưng hầu hết các mô hình đã tiến hóa để có thể nhận vào, trả ra nội dung ngoài văn bản như hình ảnh, âm thanh, video. Chúng không chỉ “đọc” mà giờ có thể “nhìn”, “nghe” và “xem”. Tuy vậy việc gọi chung là LLMs vẫn phổ biến và không sai vì hình ảnh, âm thanh, video vẫn cần chuyển đổi thành dạng vector văn bản để mô hình có thể hiểu được.
- Closed-source LLMs - là các mô hình ngôn ngữ lớn không được công khai mã nguồn, kiến trúc và dữ liệu dùng để huấn luyện. Các mô hình này được sử dụng, tiếp cận qua các sản phẩm mà tổ chức sở hữu model đó cung cấp như giao diện chat, API, tooling … Ví dụ các LLM rất phổ biến trong giới lập trình viên là:
- GPT-4 của OpenAI
- Gemini của Google
- Claude của Anthropic
- Open-Source LLMs - cũng tương tự như phần mềm mã nguồn mở, các mô hình ngôn ngữ lớn nguồn mở chia sẻ trọng số của mô hình, mã nguồn để huấn luyện, dữ liệu huấn luyện, kiến trúc của mô hình một cách rộng rãi theo một giấy phép nguồn mở nào đó (MIT/Apache 2.0) cho phép bất kỳ ai cũng có thể truy cập, sử dụng, chỉnh sửa mô hình …
- Qwen3 (235B-A22B) - Apache 2.0
- Mixtral 8x22B - Apache 2.0
- DeepSeek-V3 - MIT
- Grok - 1 - Apache 2.0
- …
- Open Weights LLMs: LLMs whose trained parameters — known as weights — are publicly available. These weights are the internal variables the model learns during training that determine how it processes input and generates output. Public access to weights enables users to inspect, fine-tune, or adapt the model for new tasks. Giấy phép: Llama 3.1 License, Gemma License
- Hugging Face là GitHub của AI nơi chia sẻ các model (model repo), datasets (dataset repo), có model-cart ~ README, quản lý bằng
git,git-lfsvà có thể clone các model/datasets bằng git (git clone [email protected]:moonshotai/Kimi-K2.5) - Parameters
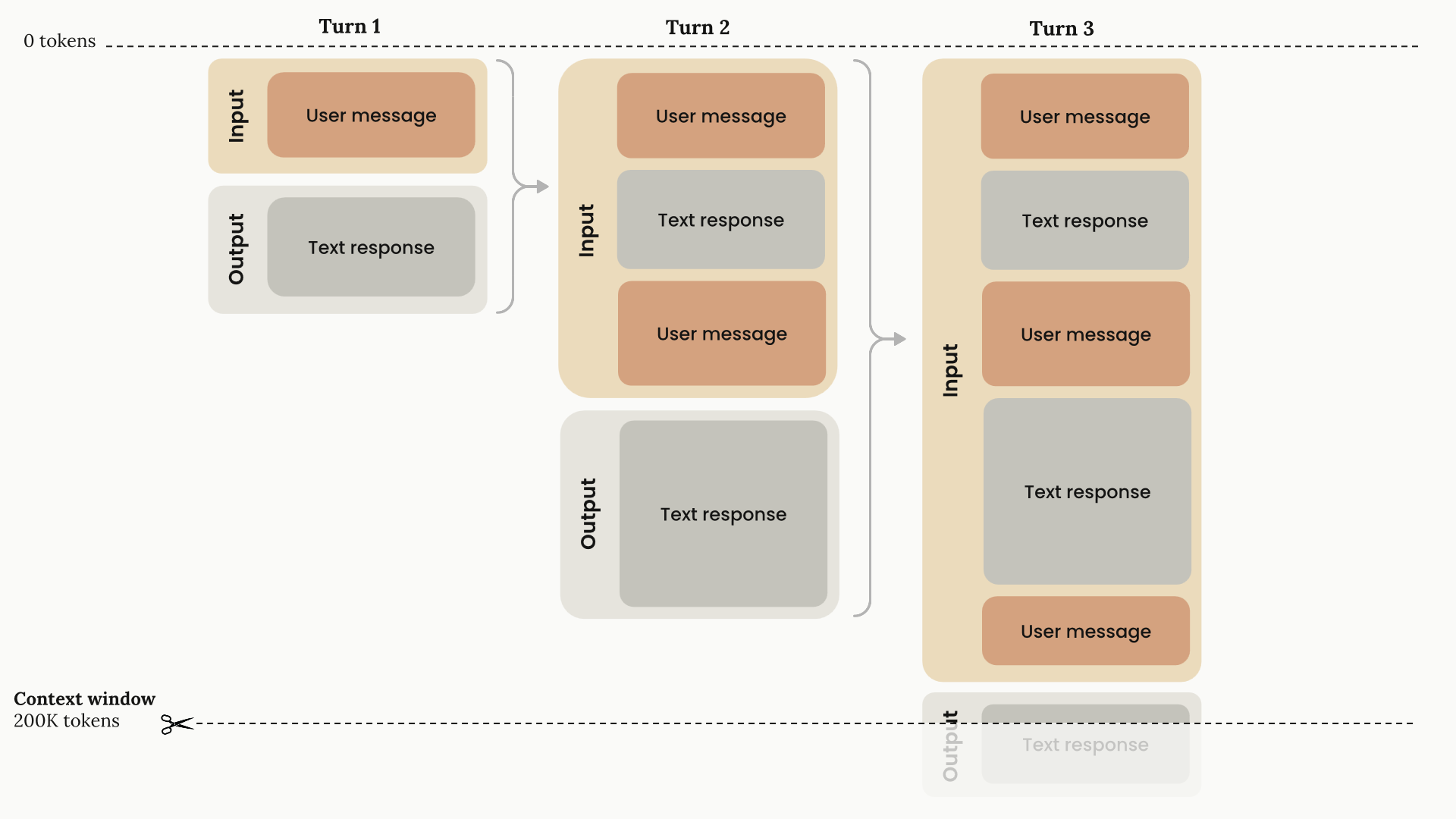
- Context Window - là số lượng token tối đa mà LLMs có thể xử lý trong một request ba gồm cả input (prompt, documents, history) và output, thường từ 4k - 1M+ (Sonet 4 - 4.5 đạt 1M, Gemini 3 đạt 2M token). Context windows được xem như working memory của model, số càng lớn, thì model càng “nhớ” lâu hơn, hiểu ngữ cảnh hơn (ví dụ trước đây bạn đã nói với model vai trò của bạn là DevOps engineer và hệ thống đang vận hành là PHP, nó sẽ dựa vào đó để liên kết tới các câu hỏi sau này, đưa ra các câu trả lời dựa trên trí nhớ đó). Context windows lớn cũng giúp các AI agent có thể đọc được nhiều code ở một repo lớn, hoặc xử lý các file văn bản với hàng trăm ngàn dòng dữ liệu.
ollama: là tool dùng để deploy, manage open-source LLMs ở local. Nó tương tựuvđể quản lý nhiều version Python. (ưu tiên dễ dùng, nên phù hợp với triển khai, thử nghiệm ở local), thích hợp với các model nhỏ, khả năng scale giới hạn, tùy chỉnh hạn chế. Bản chất ollama là một wrapper chạy trên nền llama.cpp
ollama run qwen2.5-coder:7b
Trên các môi trường production, để self-host các LLMs người ta cần các công cụ hiệu quả, cho tinh chỉnh, hiệu suất cao hơn
ollama. Dẫn tới có nhiều công cụ được sinh ra để giải quyết nhưvLLM,TGI,SGLangTGI - Text Generation Inference: Đây là sản phẩm của Hugging Face, tối ưu cực tốt cho các model họ BLOOM hoặc Llama chạy trên môi trường cloud)
vLLM: Kỹ thuật PagedAttention của vLLM giúp quản lý bộ nhớ KV Cache giống như cách hệ điều hành quản lý bộ nhớ ảo, giúp tăng throughput lên gấp nhiều lần)
SGLang:
llama.cpp: CPU-optimized inference
“Six Tigers” dominate China’s AI industry: Nói về 6 công ty AI hàng đầu của Trung Quốc:
- Zhipu AI (Z.ai - tên cuốc tế), ra đời năm 2019 bởi 2 giáo sư ĐH Thanh Hoa, một trong các generative AI sớm nhất ở TQ, có các sản phẩm như ChatGLM và AI video generator. Họ có các model như GLM-x (4 Plus, 4-Voice), mới nhất GLM-4.7.
- Moonshot AI ra đời năm 2023 cũng ở đại học Thanh Hoa, đang rất nổi gần đây nhờ model Kimi K2.5, họ có Kimi AI một trong top 5 chat bot ở TQ, cty này backed bởi Alibaba và 10cent
- MiniMax ra đời năm 2021 và có sản phẩm chatbot là Talkie và nhiều model như MiniMax M2, công ty này cũng nhận được đầu tư từ Alibaba
- Baichuan là một cty AI khác ra đời năm 2023, với đội ngũ nhân tài tới từ M$, Heo quay, Baidu 10xu, họ có 2 LLMs model lớn là Baichuan-7B và Baichuan-13B, cũng gọi đầu tư từ Alibaba và 10xu
- StepFun ra đời vào năm 2023 tại Shanghai, họ đã release 11 models từ visual, audio cho tới multimodal
- 01.AI - họ có 2 model là Yi-Lightning and Yi-Large
Fine-tuning - là quá trình lấy một mô hình chuẩn đã được huấn luyện trước đó (pre-trainned model - general information) và tiếp tục huấn luyện nó trên một tập dữ liệu chuyên biệt, nội bộ, đặc thù để hoạt động tốt cho một nhiệm vụ cụ thể (ví dụ thay vì dùng nginx từ apt repo, bạn có thể compile nginx để bỏ các module mail không cần thiết cho nhu cầu webserrver). Thay vì sử dụng một model khổng lồ, xu hướng là dùng một model nhỏ (Llama-8B, Qwen-7B) và fine-tune vì:
- Model nhỏ, ít tốn tài nguyên GPU, hardware hơn, hiệu quả về mặt chi phí
- Input các data chuyên biệt, thuật ngữ nội bộ, bộ dữ liệu đặc thù
How fine-tuning works: a step-by-step guide:
- Step 1: Data Preparation
- Step 2: Choosing an approach (Full fine-tuning, PEFT?)
- Step3: Trainning the model
- Step 4: Evaluation and deployment
axolotlvàunslothlà các công cụ dùng để huấn luyện các trong quá trình fine-tunevLLM vs Triton:
- Triton Inference Server (NVIDIA) được thiết kế cho nhu cầu tổng quát, nó hỗ trợ nhiều framework (TensorFlow, PyTorch, ONNX, JAX), nhiều loại model khác nhau (vision, speech, text) và nhiều cách deploy khác nhau (GPU, multi-GPU, multi-node). Nổi bật ở việc triển khai multimodal model (image classification, object detection, speech recognition, and embeddings.)
- vLLM tập trung vào LLMs, nổi bật ở độ trễ thấp (Continuous Batching), kỹ thuật PagedAttention quản lý bộ nhớ hiệu quả.
Inference Server - là một phần mềm trung gian giúp model được sever thành một API mà các ứng dụng khác có thể giao tiếp. Trong thế giới DevOps, inference server có thể xem như nginx đứng trước các mã nguồn như PHP.
Prompts - là các yêu cầu, chỉ thị (input, instructions) mà người dùng gửi tới model để nhận về một kết quả.
Prompt engineering là kỹ thuật, cách, nguyên tắc để viết/tạo ra các yêu cầu, chỉ thị hiệu quả, từ đó giúp các LLMs hiểu yêu cầu và trả về kết quả tốt hơn. Nhưng thay vì code, chúng ta sẽ dùng ngôn ngữ tự nhiên (tiếng Anh, tiếng Việt). Ví dụ:
❌ Vague prompt: “Write a summary.”
✅ Effective prompt: “Summarize the following customer support chat in three bullet points, focusing on the issue, customer sentiment, and resolution. Use clear, concise language.”
Prompt engineering vs Fine-tuning: Là 2 cấp độ với cùng mong đợi về kết quả là model trả về kết quả tốt hơn, trong khi fine-tuning là quá tình huấn luyện lại ở một domain cụ thể yêu cầu hiểu biết kỹ về kỹ thuật, thì prompt engineering không cần phải hiểu biết về kỹ thuật hoặc computer science.
Prompt engineering quan trọng là vì nó giúp đạt được kết quả tốt hơn, model hiểu yêu cầu hơn, (nhiều closed-source không cho phép fine-tuning), chi phí ít hơn
Gemma models là một họ nhiều model state-of-the-art, nhẹ và mở, anh em với Gemini. Khác với Gemini là model đóng, Gemma là model mở tuân theo giấy phép Gemma.
- Gemma 3 là model giải quyết nhiều tác vụ ở nhiều lĩnh vực khác nhau với input là text/image. Input context là 128K tokens cho 4B, 12B, 27B và 32 tokens cho 1B size
- CodeGemma là model tập trung vào giải quyết các công việc liên quan đến lập trình, coding
AI Agent - là một chương trình máy tính có thể tương tác với môi trường, thu thập dữ liệu, thực thi các tác vụ. Khác với chat (nhận input, trả về giải pháp) thì agent có khả năng chủ động hành động (thu thập thêm thông tin bằng cách đọc codebase, thực thi command, lập kế hoạch và tự lựa chọn phương án tối ưu). Agent khác Chatbot ở chỗ nó có vòng lặp phản hồi (feedback loop): Quan sát -> Suy nghĩ -> Hành động -> Quan sát kết quả
OpenCode - là một trợ lý lập trình AI (AI coding agent) nguồn mở (hỗ trợ terminal, web, desktop app). Tương tự GitHub Copilot hay Claude Code. Nhưng khác ở chỗ nó là phần mềm opensource, dụng được nhiều model khác nhau (thay vì bị locking bởi OpenAI, Anthropic) và có thể chạy local.
Anthropic:
- Claude Code - AI coding agent hỗ trợ terminal & IDE -> Model sử dụng là Opus 4.5 (xịn nhất hiện tại), Sonet 4.5 (nhanh) và Haiky 4.5
- Claude is a next generation AI assistant -> form chat
OpenAI:
- Codex - tương tự đối thủ là AI coding agent, hỗ trợ terminal và IDE -> Mode sử dụng là GPT-5.1-codex-max
- ChatGPT agent là AI assistant, form dùng để chat tương tự đối thủ Claude
AI coding agent - là agent chuyên biệt cho coding, thường tích hợp với IDE, termnial để có thể thu thập thông tin, code từ repo (khác với assistant phải gửi từng đoạn code hoặc upload) để hiểu hơn về mã nguồn. AI coding agent có thể hỗ trợ viết code, fix bug, review code hoặc lập kế hoạch trước khi implement code, tất nhiên các agent này vẫn sử dụng các model AI để giải quyết vấn đề.
AGENTs.md - trong khi
README.mdlà tệp để con người đọc (thông tin về dự án, quick start như thế nào, cài đặt như thế nào, kiến trúc ra sao, contribution guide …), thìAGENTs.mdlà tệp để AI Agent đọc và hiểu về dự án. Chúng ta cung cấp thông tin về dự án, build/test command, coding convention, security considerations, kiến trúc dự án, tổ chức thư mục, một số quy tắc (không được đụng vào các tệp nào, không được xóa các tập tin quan trọng nào …) để AI agent có thể hiểu hơn về dự án. Có thể xemAGENTs.mdnhư một system prompt.AgentSkills - hiểu đơn giản nó là một thư mục tập hợp các chỉ thị, script và các tài nguyên giúp agent có thể đọc, sử dụng để làm việc hiệu quả hơn. Định dạng Agent Skills ban đầu được phát triển bởi Anthropic, sau đó trở thành tiêu chuẩn mở, nhiều sản phẩm tích hợp và tuân theo chuẩn mở này. Ví dụ một skill cho Terraform.
SKILL.md - Là tệp core của một skill, chứa metadata ( name, description) và các chỉ thị để agent có thể làm một task cụ thể, có nội dung dạng như sau:
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents.
---
# PDF Processing
## When to use this skill
Use this skill when the user needs to work with PDF files...
## How to extract text
1. Use pdfplumber for text extraction...
## How to fill forms
...
> my-skill/
├── SKILL.md # Required: instructions + metadata
├── scripts/ # Optional: executable code
├── references/ # Optional: documentation
└── assets/ # Optional: templates, resources
- Major LLMs benchmarks - Các model mới được sinh ra cần chứng minh mức độ hiệu quả, chi phí và use-case nào nó làm tốt, nên chúng sẽ được đánh giá thông qua một bộ benchmark giống nhau để so sánh:
- Knowledge & reasoning
- Coding
- Math
- Comprehensive
- MLOps - là đem DevOps principles vào các hệ thống ML. Tương tự Dev và Ops, sẽ có một gap/conflict giữa “working notebook” và notebook được triển khai trên môi trường production (worked on my machine), deployment process (manual, no-rollback), CI, GitOps …
- IDE tích hợp AI - là các IDE được tích hợp các tính năng của AI và các model AI. Các IDE này thường chọn fork từ VSCode (cụ thể là VSCodium một bản fork đã loại bỏ các trình theo dõi của Microsoft). Mà tiên phong, là Cursor, Windsurf (Codeium). Thường các IDE này sẽ chọn model cỉa Anthropic hoặc OpenAI như Claude Code và GPT.
- Antigravity là một IDE tích hợp AI cũng fork từ VSCode tới từ Google, cho phép lựa chọn nhiều model khác nhau nhưng chủ yếu là Gemini, nổi bật với tính năng Agent Manager (chạy nhiều agent cùng lúc, mỗi agent làm một nhiệm vụ) và context window cực lớn tới từ Gemini model, nên có thể feed nhiều data/code/docs vào model.
- Browser Agent - hiểu đơn giản nó tương tự testing automation tool truyền thống như Selenium, Puppeteer nhưng tích hợp AI để làm các tác vụ, thao tác, tương tác trên web theo chỉ thị. Ví dụ như chụp màn hình để “nhìn” website trông như thế nào, đọc cấu trúc page, source, content (DOM access), thao tác (click, type, scroll, navigate) và thực thi … Có các tool như Browser Use hay Playwright kết hợp LLM.